The data warehouse isn’t dying. The teams declaring it obsolete are making an architecture mistake that will cost them 18 months and a painful migration to undo.
Here’s what’s really going on. The traditional data warehouse, a tightly structured and carefully governed store of clean business data, is being asked to do things it was never built for: hold raw unstructured files, run machine learning workloads, process streaming data in real time, and act as both the analytical engine and the raw data archive. When it strains under those demands, teams assume the warehouse is the problem and rush toward a lakehouse replacement.
In most cases the warehouse isn’t the problem. It’s being used for workloads that belong in a different layer of the architecture, one that complements the warehouse instead of replacing it. That distinction sits at the centre of the modern data lakehouse vs warehouse debate.
One number is worth sitting with. In the Databricks State of Data + AI report, over 60% of organisations that migrated fully from a warehouse to a data lake or early lakehouse later reintroduced warehouse-style governance and structure, because data quality, query performance, and business-user self-service all slipped without it (Databricks). The teams getting this right in 2025 aren’t the ones who abandoned warehouses. They’re the ones who understood what warehouses are good at and built the lakehouse around that foundation.
This guide lays out the real trade-offs: what warehouses are still excellent at, where they fall short, what a modern lakehouse adds, and a migration framework that helps you make the right call rather than the fashionable one.
Figure 1: The modern data platform as three connected layers, not a warehouse-or-lakehouse choice. (See editor’s notes for spec.)
Why “Warehouses Are Dead” Gets It Wrong (Mostly)
What the Data Warehouse Gets Right
The traditional data warehouse (Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse) was built around principles that still hold up:
Clean, structured, governed data. A well-run warehouse holds data that has been transformed, validated, and documented. Every table has a known structure, every column has a definition, and everything entering the warehouse has been cleaned and standardised. That’s not trivial. It takes constant work by data engineers, and it’s the reason business users can query a warehouse and trust what comes back.
Consistent query performance. Warehouses are tuned for analytical SQL on structured data. Complex aggregations, joins across large tables, and many users querying at once are exactly what they were engineered for, and the performance is predictable and manageable.
Business-user accessibility. Because warehouse data is structured and governed, analysts can reach it with SQL or BI tools without pulling in a data engineer for every query. Real self-service analytics is possible on warehouse data in a way it simply isn’t on a raw data lake.
These aren’t legacy limitations waiting to be replaced. They’re design properties that matter enormously for the roughly 80% of enterprise analytics work built on structured business data and business-user queries.
Where the Data Warehouse Falls Short
The criticism of warehouses isn’t all wrong. There are real workloads where warehouse architecture creates friction:
Unstructured and semi-structured data. Warehouses were designed for rows and columns. Images, video, audio, raw JSON logs, free text, and sensor streams don’t fit that model cleanly. Storing them in a warehouse is possible, but expensive and awkward.
Machine learning and data science. Training models usually needs raw, unaggregated data, often in formats (Parquet files, feature stores) that don’t line up with warehouse tables. Data scientists frequently need to work a layer below the governed warehouse to reach the granular data their models require.
Cost at extreme scale. Warehouse compute and storage are priced for governed analytical queries. Applied to petabytes of raw data that’s rarely queried, the economics stop making sense. Cloud object storage (S3, GCS, Azure Blob) is an order of magnitude cheaper per gigabyte.
Real-time and streaming data. Traditional warehouses are batch-oriented, with data loaded on a schedule rather than streamed continuously. For sub-minute freshness, you end up bolting on extra tooling and workarounds.
These limits are real, and they’re specific. They hit particular workloads, not every data workload. The mistake is treating them as a reason to replace the whole warehouse rather than extend it with the right complementary layer.
Key Takeaways: The Warehouse Assessment
- Warehouses excel at governed, structured analytical data and business-user access. Those properties still matter.
- They fall short on unstructured data, ML workloads, raw-storage cost, and real-time streaming.
- Over 60% of organisations that fully abandoned warehouses for data lakes reintroduced warehouse-style governance (Databricks).
- The right response to warehouse limits is extension, not wholesale replacement.
- A lakehouse isn’t a warehouse replacement. It’s a warehouse with an added raw storage and processing layer.
Want to see how this plays out on a real platform? Browse our data platform case studies for how we’ve layered governance onto messy data estates.
What a Modern Lakehouse Is (and Isn’t)
The word “lakehouse” has been stretched by enough vendors to mean almost anything, so let’s be precise.
A data lakehouse is an architecture that combines:
- Cloud object storage (Amazon S3, Google Cloud Storage, Azure Data Lake Storage) as the foundation: cheap, scalable, format-agnostic storage for raw and processed data in any format.
- An open table format (Delta Lake, Apache Iceberg, or Apache Hudi) that adds database-like behaviour to files in object storage: ACID transactions, time travel, schema enforcement, and efficient querying.
- A unified governance and metadata layer that applies consistent access control, cataloguing, and lineage across the whole data estate.
- Compute engines (Apache Spark, Trino, DuckDB) that query data directly in object storage without loading it into a warehouse first.
In practice, this means data is stored once in cheap object storage, in open formats, and queried by multiple tools: SQL for analysts, Python and Spark for data scientists, streaming engines for real-time work. The governance layer gives the estate the structure and reliability that plain data lakes never had.
What a lakehouse is not:
- A replacement for your warehouse when it comes to structured, governed analytical data.
- Simpler than a warehouse. It’s more flexible, but also more complex to build and run correctly.
- Automatically better. A poorly governed lakehouse produces worse outcomes than a well-governed warehouse.
A more accurate description of where successful teams are landing isn’t “warehouse or lakehouse.” It’s warehouse and lakehouse, with clear rules about which data lives where, and why.
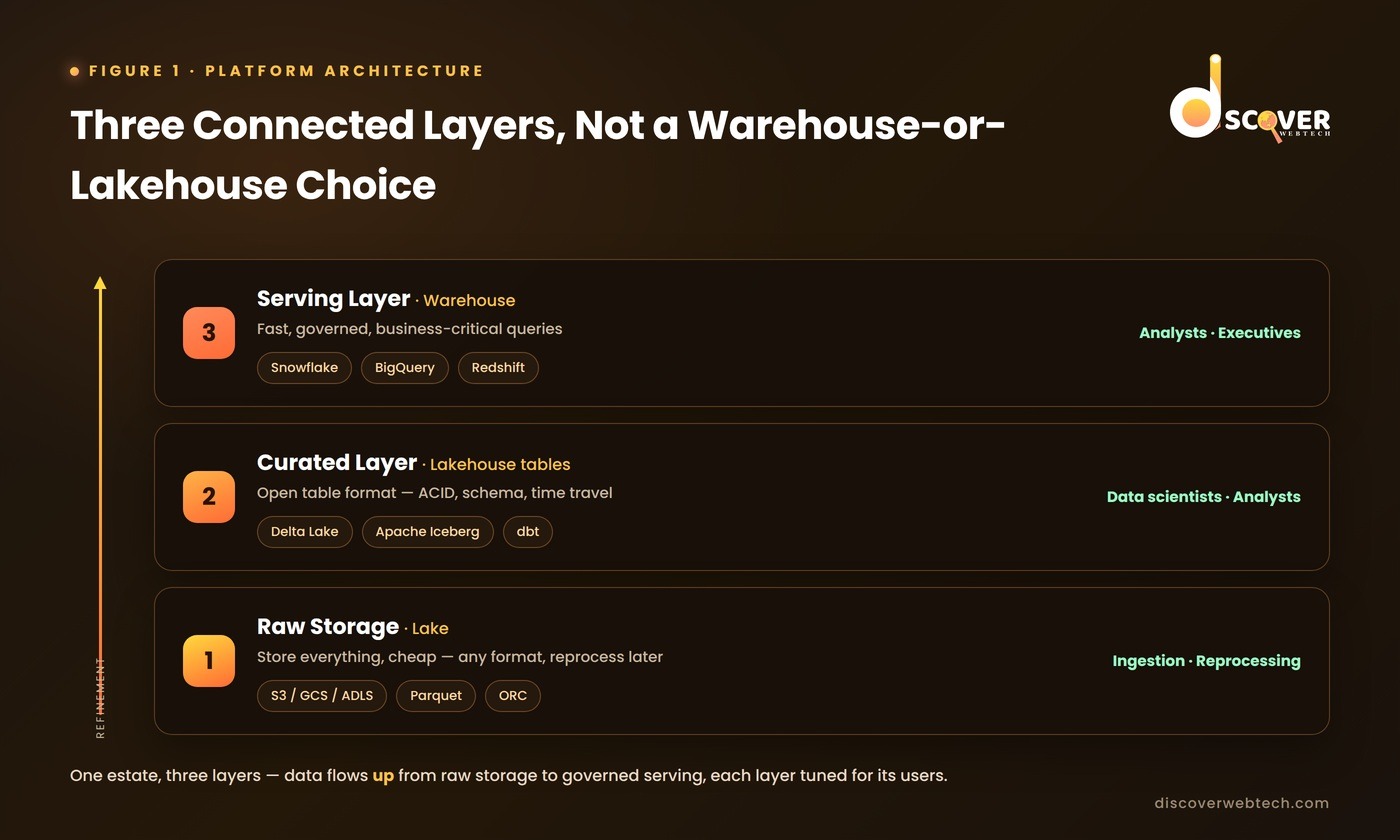
The Modern Architecture: Three Layers Working Together
A well-designed modern data platform has three layers, each serving a different purpose and a different set of users.
Layer 1: The Raw Storage Layer (the Lake)
This is where all data lands first: raw, unprocessed, in its original format. Log files, API responses, database change events, sensor data, third-party feeds, uploaded documents.
The principle here is store everything, transform later. Raw data is kept in its original state so it can be reprocessed with updated logic, picked up by use cases nobody anticipated at load time, and used for ML feature engineering that needs unaggregated data.
Storage stays cheap through cloud object storage (fractions of a penny per GB per month) and open formats (Parquet, ORC) that any compatible engine can read directly.
Layer 2: The Curated Layer (the Lakehouse Tables)
This is where transformation happens, and where the open table format does its most important work.
Raw data is cleaned, standardised, and shaped into tables using frameworks like dbt. Those tables live as open-format files in object storage but are governed by the table format (Delta Lake or Iceberg), which provides:
- ACID transactions: updates and deletes are handled correctly and consistently, something plain data lakes never managed.
- Schema enforcement: tables have defined schemas that new data must match before it’s written.
- Time travel: every version of a table is retained, so you can query historical states and roll back bad updates.
- Partition pruning and file compaction: performance optimisations that keep queries on large tables fast without a warehouse engine.
Curated-layer data is queryable by SQL tools, BI platforms, and Python workflows. It’s the primary source for both structured reporting and machine learning, including workloads like predictive customer churn models that need granular, unaggregated data.
Layer 3: The Serving Layer (the Warehouse)
This is where the warehouse earns its keep, rather than its retirement notice.
For the governed, business-critical metrics executives and analysts query all day (revenue, customer counts, operational KPIs, financial reporting), the serving layer loads curated data from the lakehouse into a warehouse engine tuned for concurrent queries and business-user access.
The warehouse here isn’t the source of truth for all data. It’s the access layer for data that needs warehouse-grade performance and governance. Engineers decide which curated tables to promote based on query frequency, business criticality, and performance needs. This is also where the quality of your real-time operational dashboards is won or lost, because a fast serving layer is what lets executives trust the numbers in front of them.
The payoff of this split:
- Raw data stays cheap and accessible in object storage.
- Data scientists work directly against curated lakehouse tables without warehouse cost.
- Analysts and BI tools get the fast, reliable, governed warehouse experience they depend on.
- ML pipelines and streaming workloads run against lakehouse data without fighting for warehouse compute.
Key Takeaways: The Three-Layer Model
- The platform has three layers: raw storage (cheap), curated lakehouse tables (governed open format), and warehouse serving (fast, BI-ready).
- Open table formats (Delta Lake, Apache Iceberg) are what separate a lakehouse from a plain data lake: ACID, schema enforcement, time travel.
- dbt is the standard framework for building curated tables from raw data.
- The warehouse specialises into the serving layer for high-frequency, business-critical queries. It doesn’t disappear.
- Data scientists work in the curated layer, analysts in the serving layer, both from the same underlying data.

The Decision Matrix: When to Use What
| Use case | Best layer | Why |
| Structured BI and executive reporting | Warehouse serving layer | Built for concurrent SQL, BI tool integration, business-user access |
| ML feature engineering and model training | Lakehouse curated layer | Granular data, cost-effective compute, Python-native |
| Raw data archival and reprocessing | Raw storage layer | Cheapest storage, format-agnostic, reprocess later with new logic |
| Real-time operational dashboards | Streaming pipeline to lakehouse | Open table formats support streaming writes; warehouse refresh is too slow |
| Data exploration and discovery | Lakehouse curated layer | Ad-hoc queries without warehouse cost, schema-on-read flexibility |
| Financial close and regulatory reporting | Warehouse serving layer | ACID guarantees, audit trail, strict governance |
| Large-scale log analytics | Lakehouse curated layer | Log volumes make warehouse storage cost prohibitive |
| Cross-departmental data sharing | Unified lakehouse governance layer | Single access-control and lineage layer across all assets |
Migration Roadmap: Adding a Lakehouse Without Ripping Out the Warehouse
For a team with an established warehouse, the question isn’t “how do we replace it?” It’s “how do we add the lakehouse layer where it creates value without disrupting what already works?”
Phase 1: Assessment and Architecture Design (Weeks 1 to 6)
Map your current data estate honestly: what lives in the warehouse, how it got there, who uses it, and what the query patterns look like. Find where the warehouse creates friction, usually ML workloads, raw-storage cost, or datasets too large or granular for cost-effective warehouse storage.
Then define the target state: which datasets move to the lakehouse, which stay in the warehouse serving layer, and how data flows between them. Pick your open table format (Delta Lake if you’re Databricks-centric, Apache Iceberg if you want maximum flexibility across engines).
Phase 2: Foundation and Pilot Migration (Months 2 to 4)
Build the raw storage layer in your cloud provider’s object storage. Implement the open table format on your highest-priority curated dataset, typically the one driving the most warehouse cost or the most pain for your data science team.
Run that lakehouse dataset in parallel with the matching warehouse table for at least 30 days and compare results. Only retire the warehouse table once you’re confident the lakehouse version is producing consistent, reliable output.
Phase 3: Full Migration and Optimisation (Months 4 to 12)
Migrate the remaining datasets to the right layer using the decision matrix above. Move your transformation pipelines to dbt against the curated layer. Update BI connections where it makes sense, keeping the warehouse serving layer for high-frequency business reporting.
For most teams the full migration runs 6 to 12 months, not the 3-month timeline vendors like to quote. Budget for parallel-running costs along the way, because you’ll pay for both architectures at once for a stretch.
Total Cost of Ownership: The Real Numbers
The main financial driver for lakehouse adoption is storage and compute cost at scale. Here’s how the economics compare:
| Cost component | Warehouse only | Lakehouse + warehouse |
| Storage (per TB/month) | £20 to £50 (warehouse storage) | £0.02 to £0.05 (object storage for raw/curated) plus £20 to £50 (warehouse for serving layer only) |
| Compute (analytical queries) | Warehouse compute rates | Mixed: cheaper Spark/Trino for lakehouse, warehouse compute for serving layer |
| Data science compute | Warehouse compute (expensive) | Separate cluster compute (often 60 to 80% cheaper) |
| Governance tooling | Usually included in warehouse licensing | Extra cost for data catalog and metadata management |
| Engineering complexity | Lower (one platform) | Higher (multiple components to manage) |
The lakehouse cost advantage is largest when data volumes are big (petabyte scale), data science workloads are substantial, and raw data needs to be kept for long periods. For smaller volumes (under 5TB), the operational complexity of a full lakehouse often outweighs the savings, and a well-configured warehouse stays the right call.
The Bottom Line
The data warehouse isn’t legacy tech on borrowed time. It’s a mature, reliable, well-understood platform for the structured, governed analytical work at the core of enterprise BI. It earns its place in the modern architecture, just not as the only layer in it.
The lakehouse adds real value: cheaper raw storage, better support for ML, flexibility for large-scale unstructured data, and an open-format foundation that avoids vendor lock-in. But it adds that value as a complement to the warehouse, not a replacement for it.
The teams getting data architecture right in 2025 have stopped asking “warehouse or lakehouse?” and started asking “which workloads belong in which layer, and how do they connect?” That’s a harder question to answer, and it’s the one worth asking.
If you’d rather not map that out alone, our data and dashboards team can help you decide which workloads belong where before you commit to a migration.
Weighing a lakehouse move? Book a free architecture review and we’ll tell you honestly whether you need one, and where a warehouse still wins.
Frequently Asked Questions
A data lake is a storage system, usually cloud object storage, where data is kept raw and unprocessed in any format. It’s cheap and flexible but historically hard to govern: no schema enforcement, no ACID transactions, poor query performance on large datasets, and limited business-user access. A lakehouse adds an open table format (Delta Lake, Apache Iceberg, or Apache Hudi) on top of that storage. The format brings ACID transactions, schema enforcement, time travel, and query optimisations, giving the lake the governance and reliability that used to exist only in warehouses.
A warehouse stores structured, transformed, governed data tuned for analytical SQL and concurrent business-user access. A lakehouse stores data in open formats in cheap object storage, with a table format providing ACID guarantees and governance, and it handles structured, semi-structured, and unstructured data. The practical difference: warehouses give consistent performance for governed reporting, while lakehouses give flexibility, cheap storage at scale, and support for ML alongside analytics. Most modern platforms use both in complementary roles rather than choosing one.
Both are open table formats, software layers that sit on top of object-storage files (usually Parquet) and add database-like behaviour. They provide ACID transactions (reliable updates and deletes), schema enforcement (new data must match the table’s structure), time travel (query the table as it was at any earlier point), and partition management (efficient querying of large datasets). These capabilities are what separate a lakehouse from a plain data lake. Delta Lake is mainly associated with Databricks; Apache Iceberg is more engine-agnostic and supported natively by Snowflake, AWS, Google BigQuery, and most major query engines.
The lakehouse gives the most value when data volumes are large (multi-terabyte or petabyte scale), ML and data science workloads are significant alongside BI, data types include unstructured or semi-structured content, or warehouse storage cost at scale is becoming prohibitive. For teams with smaller volumes (under 5TB), mostly structured data, mostly analyst users, and no significant ML, a well-configured warehouse stays simpler and often more cost-effective than running a full lakehouse.
DBT is a transformation framework that lets data teams write, test, document, and version-control transformations in SQL or Python. In the modern stack it sits between the raw storage layer and the curated layer, defining the logic that turns raw data into clean, governed tables. It brings software-engineering practices (version control, testing, documentation) to transformation work. dbt runs on both warehouse platforms (Snowflake, BigQuery, Redshift) and lakehouse platforms (Databricks, Apache Spark), which makes it the de facto standard across both.
For most teams a proper migration, including assessment, pilot, and full migration with parallel running, takes 6 to 12 months, not the 3-month timeline vendors often suggest. A realistic breakdown: about 6 weeks for assessment and design, 2 to 4 months for pilot migration of priority datasets, and 4 to 8 months for full migration with parallel-running periods per major dataset. Budget for dual-running costs during the migration. Teams that rush it usually hit data quality issues and business disruption that set the project back further than a careful migration would have.