Every RAG demo works. The documents get retrieved. The answer looks accurate. The stakeholders are impressed. Then you deploy it against real data at real scale and discover that what worked in a controlled notebook environment behaves very differently when it has to handle 10,000 documents, ambiguous user queries, and the institutional knowledge of an entire organisation.
This is the RAG gap the distance between a proof-of-concept that retrieves the right passage from three carefully chosen documents and a production system that reliably answers complex questions across a messy, sprawling enterprise knowledge base.
According to a 2024 survey by Weights & Biases, 68% of teams that deployed RAG systems in production reported significant performance degradation compared to their development environment slower responses, lower answer quality, and increased hallucination rates. The gap is not a model quality problem. It is an engineering problem specifically, a series of architectural decisions that look inconsequential in demos and become critical in production.
This article covers the engineering decisions that matter most: how you split documents, how you retrieve relevant content, how you improve retrieval quality, how you stop the model making things up, and how you measure whether any of it is working. Written for engineers and technical leaders who need to build RAG systems that work in the real world, not just in demos.
What RAG Is and Why It Matters in Plain English
RAG stands for Retrieval-Augmented Generation. The name describes exactly what it does: before generating an answer, the system retrieves relevant information from a knowledge base and augments the prompt to the language model with that information.
Here is why this matters. Large language models like GPT-4 or Claude have enormous general knowledge baked into them from training. What they don’t have is your organisation’s specific knowledge your internal policies, your product documentation, your case notes, your contracts, your research. And because they were trained up to a certain date, they also don’t know about anything that happened after that cutoff.
Without RAG, when you ask an enterprise AI “what is our refund policy for software licences purchased after January 2025?”, the model either makes something up (hallucination) or tells you it doesn’t know. With RAG, the system first searches your internal knowledge base for the relevant policy document, pulls the relevant passage, and gives the model that information to work with before generating an answer. The answer is grounded in your actual documents rather than the model’s general knowledge.
RAG versus fine-tuning the simple version: Fine-tuning means retraining the model itself on your organisation’s data — expensive, time-consuming, and best for teaching the model a new style, tone, or task type. RAG means giving the model your documents as context at query time — faster, cheaper, and better suited for knowledge retrieval use cases. For most enterprise knowledge management applications, RAG is the right starting point.
The challenge is that a RAG system has several moving parts and the decisions made in each of them determine whether the system reliably retrieves the right information or consistently retrieves the wrong thing.
The RAG Architecture in Plain Language
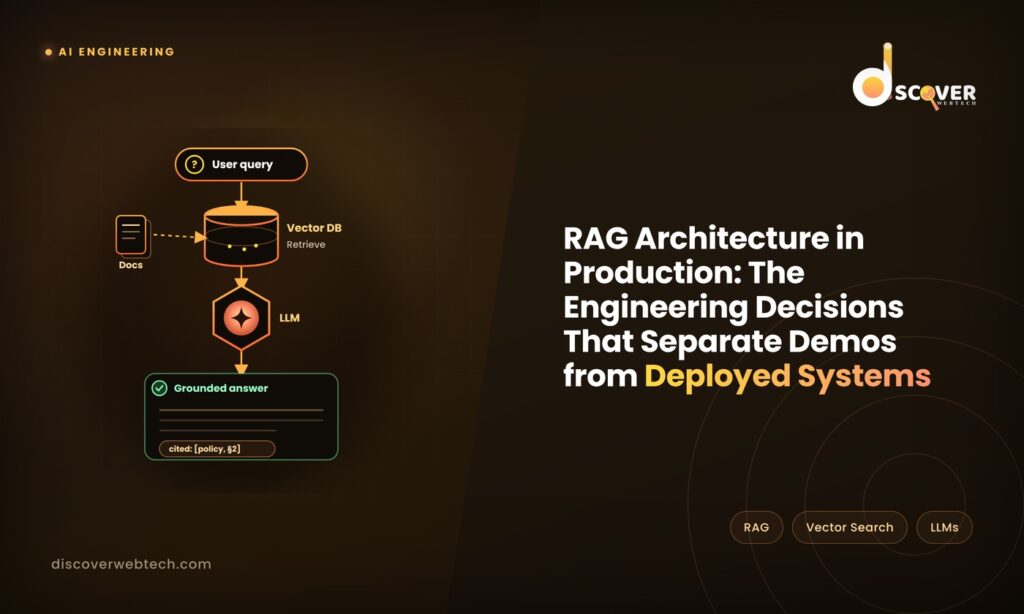
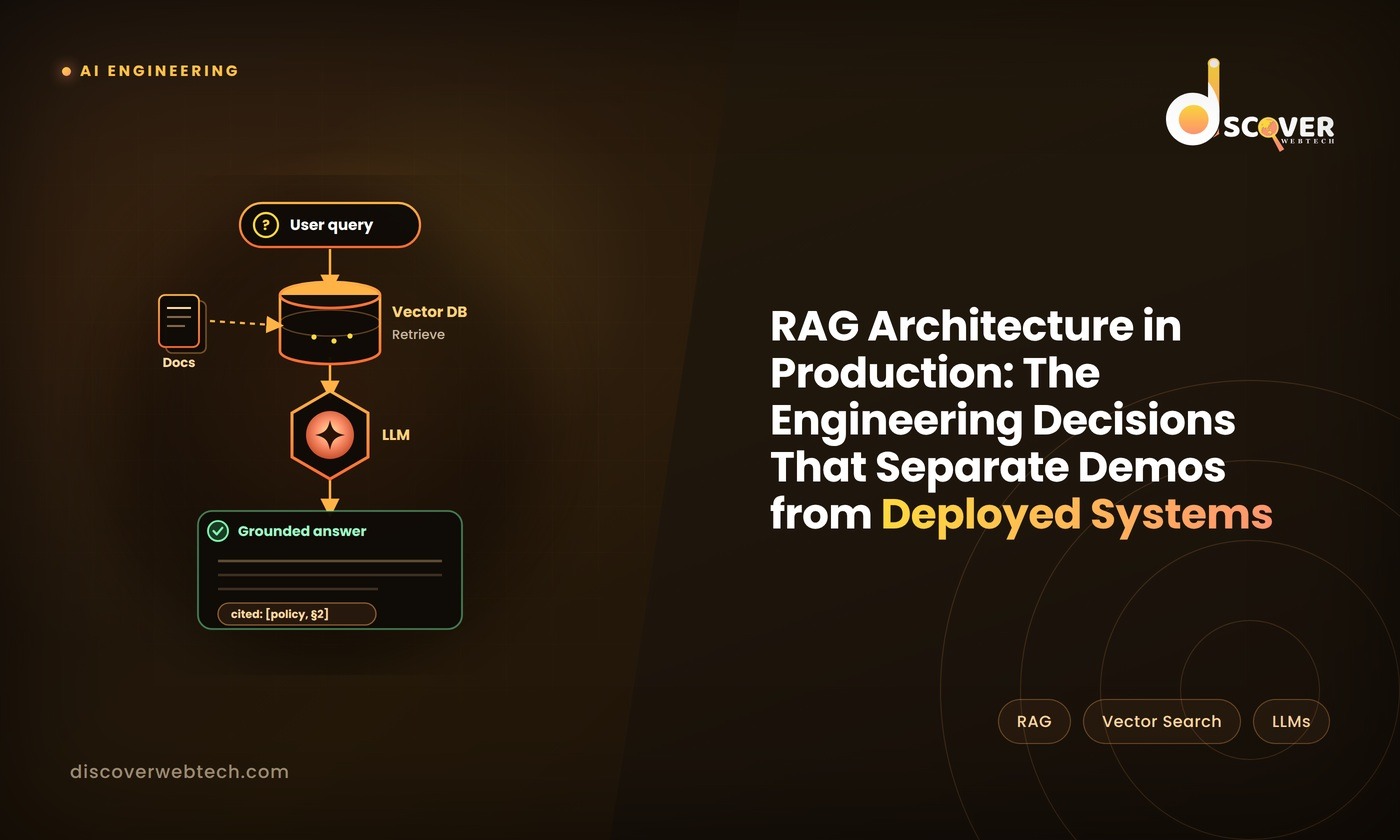
A production RAG system has two main processes that work together: indexing (preparing your documents for retrieval) and querying (finding and using the right documents when a user asks a question).
Indexing process happens once, then updated as documents change:
- Documents are loaded from your knowledge base (PDFs, Word files, SharePoint, databases)
- Documents are split into smaller chunks manageable pieces of text
- Each chunk is converted into a numerical representation called an embedding a way of encoding the meaning of the text so similar concepts end up mathematically close to each other
- The embeddings are stored in a vector database a specialised database designed for fast similarity search
Querying process happens every time a user asks a question:
- The user’s question is converted into an embedding using the same embedding model
- The vector database finds the document chunks whose embeddings are most similar to the question’s embedding — these are the chunks most likely to contain a relevant answer
- The retrieved chunks are assembled into a context window alongside the original question
- The language model generates an answer based on the question and the retrieved context
- The answer is returned to the user
This is the happy path. In a demo with three clean PDF documents and precisely worded test questions, every step works smoothly. In production, each step introduces failure modes that need to be designed around.
The Engineering Decisions That Actually Matter in Production
Decision 1: How You Split Documents (Chunking Strategy)
Chunking is how you divide your documents into pieces small enough for the model to process effectively but large enough to contain meaningful, coherent information. It sounds like a detail. It is not. Poor chunking is the single most common cause of RAG systems that retrieve technically relevant documents but fail to surface the specific information that answers the question.
The core tension: smaller chunks give the retrieval system more precision it can find the specific paragraph that answers a question rather than a page that mentions related topics. But smaller chunks lose context a sentence pulled from the middle of a technical explanation may be meaningless without the surrounding paragraphs.
The most important chunking decisions:
Fixed-size vs. semantic chunking Fixed-size chunking splits documents every N characters or tokens regardless of content simple to implement, often problematic because it cuts through sentences and paragraphs mid-thought. Semantic chunking splits at natural content boundaries paragraph breaks, section headings, logical topic shifts. Semantic chunking takes more engineering effort but produces chunks that are coherent units of meaning rather than arbitrary text fragments.
Chunk size and overlap For most enterprise knowledge base applications, chunk sizes between 300–800 tokens with a 10–15% overlap between adjacent chunks work well as a starting point. The overlap means that information near chunk boundaries appears in both adjacent chunks, reducing the risk of the relevant passage being split across two chunks and neither one retrieved. Test different sizes against your specific document types — legal contracts, technical documentation, and customer support FAQs all have different optimal chunk sizes.
Metadata attachment Every chunk should carry metadata: the source document name, the section it came from, the date the document was created or last updated, and any relevant category tags. This metadata serves two purposes: it allows the system to filter retrieval by metadata properties (only retrieve from documents updated in the last 12 months) and it provides citation information when the answer is returned to the user.
A healthcare organisation we worked with was deploying RAG over clinical guidelines that were updated regularly. Without date metadata on chunks, the system was retrieving outdated guidance with the same confidence as current guidance. Adding and filtering on document date metadata was the single change that made the system trustworthy for clinical staff.
Decision 2: How You Retrieve (Retrieval Strategy)
Once documents are chunked and indexed, the retrieval system needs to find the right chunks when a user asks a question. The default approach dense retrieval, where the user’s question and document chunks are compared by embedding similarity works well for semantically similar questions. It has known failure modes that production systems need to address.
Dense retrieval (embedding-based similarity search) is strong at finding chunks that mean the same thing as the query, even when they use different words. If a user asks “how do I cancel my subscription?” and your documentation says “procedure for terminating your service agreement”, dense retrieval connects them by meaning.
Sparse retrieval (keyword-based search, like BM25) is strong at finding chunks that contain the exact words in the query important for product names, technical identifiers, error codes, and proper nouns that embeddings handle poorly. If a user asks about “Error code E-4471”, an embedding-based search may retrieve documents about “error handling” in general rather than the specific error code entry.
Hybrid retrieval combining dense and sparse retrieval and blending their results consistently outperforms either approach alone in production environments. Most modern vector databases (Pinecone, Weaviate, Qdrant) support hybrid retrieval natively. For new production deployments, hybrid retrieval should be the default, not the optimisation.
Query rewriting Users rarely phrase their questions in a way that matches how information is written in documents. “Why does the app crash when I try to export?” is not how your documentation describes the export bug. Query rewriting using a language model to rephrase the user’s question into forms more likely to match document language, and running multiple retrieval queries significantly improves recall for complex or ambiguously worded questions. It adds latency and cost; for user-facing applications where answer quality is business-critical, it is worth both.
Decision 3-Re-Ranking: The Step That Transforms Retrieval Quality
Retrieval returns a set of candidate chunks the top-K most similar to the query. But similarity is not the same as relevance. The chunk that scores highest in embedding similarity may not be the chunk that best answers the specific question asked.
Re-ranking addresses this with a second, more expensive evaluation pass. After retrieval identifies the top-K candidates (say, the top 20), a cross-encoder re-ranker evaluates each candidate against the specific query in full detail not by comparing pre-computed embeddings, but by reading the question and the chunk together and scoring their relevance precisely. The top 3–5 results from re-ranking are passed to the language model.
The improvement in answer quality from adding re-ranking is typically the largest single gain available after the initial architecture is in place. It adds latency (the cross-encoder needs to evaluate potentially 20 pairs) and cost (an additional model call per query). For applications where retrieval quality directly affects user trust and business outcomes internal legal research, clinical decision support, enterprise customer service re-ranking is essential.
Cross-encoder models available as APIs or for self-hosting include Cohere Rerank, Jina Reranker, and several open-source options on Hugging Face. For most production applications, the managed API options are the right starting point.
Decision 4 – Controlling Hallucination in Production
The most common complaint about RAG systems in production is not slow retrieval or poor document coverage it is answers that are confidently wrong. The model retrieves relevant context, but still produces answers that go beyond, contradict, or subtly misrepresent what the retrieved documents actually say.
Why hallucination happens even with good retrieval:
- Retrieved chunks provide partial information, and the model fills the gap with plausible-sounding invented content
- The model has strong prior beliefs about a topic from training data that override what the retrieved document says
- The retrieved chunks are genuinely ambiguous, and the model resolves the ambiguity in a direction the document doesn’t support
The most effective controls:
Constrained generation prompting Instruct the model explicitly: “Answer the question using only the information in the provided context. If the context does not contain sufficient information to answer the question, say so do not infer or add information from outside the provided documents.” This prompt instruction alone reduces hallucination rates significantly for most enterprise RAG applications.
Citation requirements Require the model to cite specific chunks in its response “according to [document name, section]”. This forces the model to ground its answer in specific retrieved content and makes it easier for users to verify answers. It also makes hallucinations visible: an answer without a valid citation is a signal that the model is generating rather than retrieving.
Confidence scoring and fallback For high-stakes applications, implement a confidence evaluation step: after the model generates an answer, a secondary evaluation checks whether the answer is actually supported by the retrieved context. If confidence is low, the system can return a fallback response (“I don’t have reliable information about this please consult [authoritative source]”) rather than a potentially wrong answer.
KEY TAKEAWAYS — The Four Critical Decisions
- Chunking strategy determines retrieval precision semantic chunking with metadata outperforms fixed-size splitting in production
- Hybrid retrieval (dense + sparse) consistently outperforms either approach alone it should be your default
- Re-ranking with a cross-encoder model is the single highest-impact optimisation after the initial architecture is live
- Constrained generation prompting and citation requirements are the most practical hallucination controls
- 68% of production RAG systems underperform their demos the gap is engineering decisions, not model quality
The Decision Matrix: Build vs. Buy vs. Use a Framework
| Component | Build From Scratch | Use an Open-Source Framework | Managed Service |
| Document ingestion & chunking | Full control over chunking logic | LangChain, LlamaIndex — production-ready, highly configurable | Azure Document Intelligence, AWS Textract — best for complex document formats |
| Embedding generation | Not recommended — use APIs | — | OpenAI text-embedding-3, Cohere Embed, Voyage AI — start here |
| Vector database | Not recommended for production | Qdrant, Weaviate, Chroma (self-hosted) | Pinecone, Weaviate Cloud, pgvector on managed Postgres |
| Re-ranking | Possible with open-source models | Hugging Face cross-encoders | Cohere Rerank, Jina Reranker — easiest path |
| LLM generation | — | Ollama for self-hosted models | OpenAI, Anthropic, Google — most production deployments |
| Observability & evaluation | Complex to build well | — | LangSmith, Arize AI, Ragas (open-source evaluation) |
Recommended starting stack for most enterprise RAG deployments:
- LangChain or LlamaIndex for orchestration
- OpenAI or Voyage AI for embeddings
- Pinecone or Weaviate Cloud for vector storage (removes infrastructure management)
- Cohere Rerank for re-ranking
- GPT-4o or Claude 3.5 Sonnet for generation
- LangSmith for observability and evaluation
- Ragas for automated RAG evaluation metrics
Evaluating Whether Your RAG System Is Actually Working
This is the section most teams skip until something goes wrong. RAG evaluation in production requires measuring three things:
Retrieval quality – Is the system finding the right documents?
- Recall: of all the documents that should be retrieved for a given query, what percentage are actually retrieved?
- Precision: of the documents retrieved, what percentage are actually relevant?
- Test with a curated set of question-answer pairs where you know which documents should be retrieved
Answer faithfulness – Is the answer supported by the retrieved documents?
- Does the answer contain claims that are not present in the retrieved context? (Hallucination)
- Are citations accurate does the cited chunk actually contain the information attributed to it?
- Tools: Ragas (open-source), ARES, or custom LLM-as-judge evaluation
Answer relevance – Does the answer actually address what was asked?
- Does the response answer the question that was asked, or a related but different question?
- Especially important for ambiguous queries where the system retrieves technically relevant but practically unhelpful context
Establish baseline metrics for all three dimensions before deployment and monitor them continuously in production. Retrieval quality and answer faithfulness degrade over time as your knowledge base grows and changes without monitoring, you won’t know until users start complaining.
Common Architecture Mistakes and the Fix
Mistake: Retrieving too many chunks (large K) Retrieving 20 chunks to give the model more context sounds helpful. It often hurts. More chunks mean a longer context window, higher inference cost, more noise for the model to filter, and critically models that perform worse when given excessive context compared to a tightly focused set of 3–5 highly relevant chunks. Start with K=5 after re-ranking.
Mistake: Using one embedding model for indexing and a different one for querying Embeddings only work for retrieval when the same model that created them is used to embed queries. If you index documents with one model and then swap to a newer, better model for queries, your entire index is incompatible and needs to be rebuilt. Document your embedding model version from day one and plan for re-indexing when you upgrade.
Mistake: No document freshness management As your knowledge base evolves policies change, products update, documentation is revised — your vector index becomes stale. Old document versions continue to be retrieved alongside new ones, and users get contradictory answers. Implement a document freshness pipeline: when a document is updated, re-chunk, re-embed, and update the index. Delete the old chunks. This is operational work that is easy to skip and expensive to ignore.
Mistake: Building evaluation as an afterthought If you can’t measure retrieval quality and answer faithfulness, you can’t improve the system. Build evaluation tooling before you go to production, not after the first complaint arrives.
Conclusion
RAG is a well-understood architecture with well-understood failure modes. The gap between a demo and a production system is not a mystery it is a predictable set of engineering decisions, each of which trades off simplicity against quality, speed against accuracy, cost against reliability.
The teams that build RAG systems that stay trustworthy in production are the ones that treat each decision deliberately: they choose their chunking strategy based on their document characteristics, they implement hybrid retrieval rather than accepting the default, they add re-ranking before declaring the system production-ready, and they build evaluation infrastructure before the first user complaint arrives.
The technology is accessible. The frameworks are mature. What separates reliable production RAG from expensive hallucination machines is engineering discipline applied to the right decisions in the right order.
Frequently Asked Questions
RAG is an AI architecture that improves the accuracy of language model responses by retrieving relevant documents from a knowledge base before generating an answer. Instead of relying solely on the model’s general training knowledge, a RAG system searches your organisation’s specific documents policies, manuals, case notes, contracts and provides that content to the model as context. This dramatically reduces hallucination for knowledge-specific questions and keeps answers current without requiring expensive model retraining. RAG is used in enterprise AI because it makes AI assistants reliable for organisation-specific information without the cost and complexity of fine-tuning.
Fine-tuning involves retraining the language model itself on your organisation’s data modifying the model’s weights to change its behaviour, tone, or knowledge. RAG leaves the model unchanged and instead provides your documents as context at query time. Fine-tuning is best for changing how a model behaves (its style, tone, or approach to a task type). RAG is best for grounding a model’s answers in specific, up-to-date documents. Fine-tuning is significantly more expensive and time-consuming; RAG can be implemented in days. For most enterprise knowledge management use cases, RAG is the right starting architecture.
A vector database is a specialised database designed to store and search numerical representations of text (called embeddings) by similarity. Traditional databases search by exact value match find records where field = value. Vector databases search by meaning find the documents most semantically similar to this query. This is what makes RAG retrieval work: when a user asks a question, the system finds documents that are meaningfully related to the question even when they use different words. Common vector database options include Pinecone, Weaviate, Qdrant, and pgvector (a Postgres extension).
Chunking is how you divide documents into pieces for indexing and retrieval. It matters enormously because the chunk is the unit of retrieval the system can only return chunks, not entire documents. If chunks are too small, they lose the surrounding context needed to understand them. If they’re too large, the retrieval system can’t pinpoint the specific relevant passage. Poor chunking is the most common root cause of RAG systems that retrieve technically related documents but consistently fail to surface the specific information that answers the question. Semantic chunking (splitting at natural content boundaries) with metadata attachment and appropriate chunk overlap produces significantly better results than simple fixed-size splitting.
Re-ranking is a second evaluation pass that takes the top-K candidates retrieved by initial vector search and uses a more precise cross-encoder model to score each candidate against the specific query. Where vector search compares pre-computed embeddings, re-ranking reads the question and each candidate chunk together and scores their relevance in full detail. The result is a more accurate ranking of retrieved candidates, with the most genuinely relevant chunks surfaced to the top. It adds latency and cost (an additional model call per query). For production applications where answer quality directly affects user trust customer service, legal research, clinical decision support re-ranking is consistently worth the investment.
Production RAG evaluation requires measuring three dimensions: retrieval quality (are the right documents being found — precision and recall against a labelled test set), answer faithfulness (does the generated answer stay within what the retrieved documents say, without hallucinating), and answer relevance (does the answer address what was actually asked). The open-source Ragas framework provides automated metrics for all three dimensions and integrates with LangChain and LlamaIndex. LangSmith provides production monitoring and tracing. Baseline these metrics before deployment and monitor them continuously — retrieval quality and faithfulness both degrade as knowledge bases grow and change.
Hallucination in RAG happens when the model generates content that goes beyond, contradicts, or misrepresents the retrieved documents. Common causes include: retrieved chunks that provide partial information (the model fills the gap with plausible-sounding inventions), conflicting information across retrieved chunks, and the model’s pre-trained knowledge overriding what the documents say. The most effective controls are: constrained generation prompting (explicitly instructing the model to answer only from the provided context and acknowledge when information is insufficient), citation requirements (forcing the model to attribute claims to specific chunks), and confidence scoring with graceful fallback responses for low-confidence answers.