
A single AI agent is impressive. A team of AI agents that coordinate, divide work, and check each other’s outputs is a fundamentally different kind of technology.
Most enterprise organisations are still thinking about AI as a single assistant, one model, one task, one response. That mental model made sense for the first generation of enterprise AI tools. It is increasingly inadequate for what production AI deployments actually require.
Consider what a complex enterprise workflow actually looks like. A customer submits a support request that touches three departments. A procurement decision requires legal review, financial modelling, and supplier data. A marketing campaign needs research, copy, design direction, and compliance checking. These are not single-step tasks. They are multi-step workflows involving different types of expertise exactly the kind of work that multi-agent AI systems are built to handle.
According to Gartner’s 2025 AI Hype Cycle report, multi-agent AI systems are the single most transformative architectural pattern in enterprise AI for the next three years — ahead of fine-tuning, RAG, and AI copilots combined. The organisations that understand how to architect these systems today are building a capability that their competitors will spend the next two years trying to replicate.
This article is the architectural blueprint: what multi-agent systems are, how the key components work, what to build versus buy, and the failure modes that destroy production deployments before they deliver value.
What Multi-Agent Systems Are — In Plain English
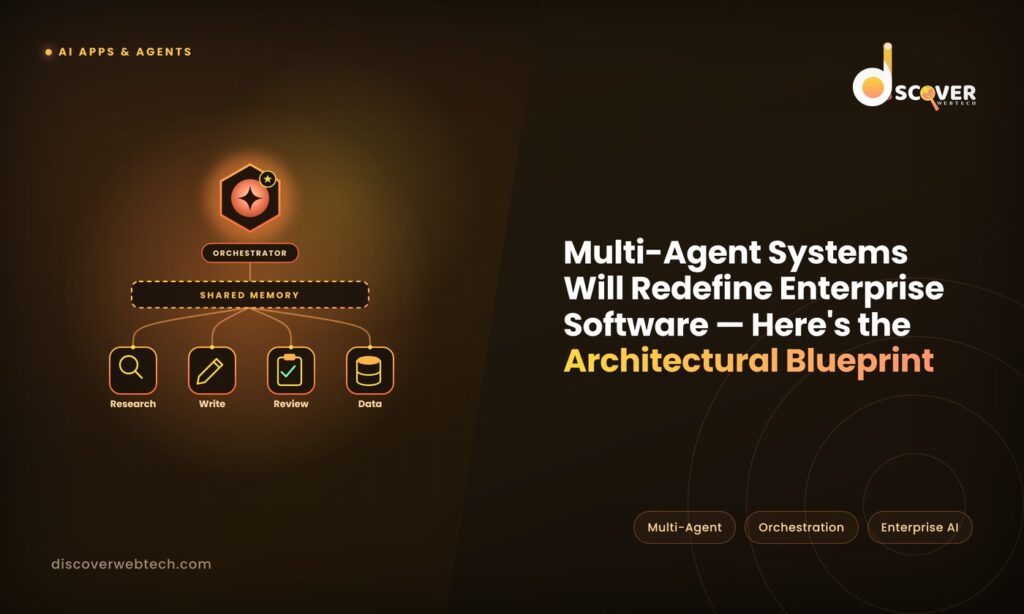
A multi-agent AI system is a design where multiple AI agents work together to complete a task — each agent specialising in a specific type of work, and a coordinating layer managing how they collaborate.
The best way to understand it is by contrast.
A single AI agent is like one very capable employee working alone. You give them a task, they work through it top to bottom, and they hand you a result. They can use tools, look things up, and take actions — but it’s one entity doing all the work.
A multi-agent system is like a small, specialist team. There’s a project manager who breaks the work into tasks and coordinates who does what. There are specialists — one who’s good at research, one who writes, one who checks for errors, one who handles external systems. The project manager assigns work to the right specialist, collects their outputs, and assembles the final result.
Here’s a concrete enterprise example: a company wants to use AI to handle complex customer contract renewals.
A single AI agent approach might struggle — the task requires legal interpretation, financial analysis, CRM data lookup, and a communication that matches the company’s tone guidelines. One generalist agent would need to do all of this sequentially and would likely produce mediocre results across several dimensions.
A multi-agent approach assigns each component to a specialised agent: one agent handles the legal review, one pulls and analyses the financial history, one queries the CRM for relationship context, one drafts the communication, and an orchestrator coordinates their work and assembles the final output. Each specialist agent does one thing well. The result is better than any single agent could produce.
The Architecture in Plain Language
A production-ready multi-agent system has five architectural components. Understanding what each one does — and where the design decisions that matter most live — is the starting point for building one that actually works.
Component 1 — The Orchestrator: The System’s Project Manager
The orchestrator is the brain of the multi-agent system. It receives the initial task, decides how to break it down, assigns sub-tasks to the appropriate specialist agents, manages the sequence of work, collects outputs, and handles what happens when something goes wrong.
In practice, the orchestrator is itself an AI model — typically a capable general-purpose LLM like GPT-4o, Claude 3.5 Sonnet, or Gemini 1.5 Pro — that has been given specific instructions about how to manage the workflow and which agents are available to assign work to.
The most important design decision for the orchestrator is its task decomposition logic: how it decides to break a complex goal into sub-tasks. This is where most multi-agent architectures either succeed or struggle. If the orchestrator splits work well, each specialist agent gets a clearly scoped task it can handle reliably. If the orchestrator splits work poorly — tasks that are too vague, too overlapping, or in the wrong sequence — the downstream agents produce inconsistent or contradictory outputs.
Think of it this way: even with a team of excellent specialists, a bad project manager produces chaos. The orchestrator is your project manager. Invest in its design accordingly.
Component 2 — Specialist Agents: The Workers Who Do the Actual Work
Specialist agents are individual AI models or AI-powered modules that are each optimised for one specific type of task.
There are two approaches to building specialist agents, and the choice matters:
Approach A — Different models for different tasks Use a powerful (and expensive) model for complex reasoning tasks, a faster (and cheaper) model for simpler tasks like summarising or formatting, and specialised models for domain-specific work (a code generation model for programming tasks, a financial analysis model for numerical reasoning). This approach optimises cost and capability — you’re not paying for a top-tier model to do work that a smaller, cheaper model handles just as well.
Approach B — Same model, different system prompts Use one capable foundation model for all agents, but give each agent a different system prompt that focuses its behaviour on a specific task. This is simpler to build and maintain. It trades some performance efficiency for operational simplicity — often the right choice for a first production deployment.
Most mature multi-agent architectures eventually blend both approaches: a capable general model for complex agents, with cheaper specialised models handling high-volume, lower-complexity tasks.
Component 3 — The Memory System: What Agents Know and Remember
Agents in a multi-agent system need memory — but memory works differently here than it does for a single chatbot.
There are three types of memory to design for:
Working memory is what an individual agent holds in context during a single task — the information it needs right now to complete its current assignment. This is managed through the model’s context window (the amount of text it can “see” at once). As tasks get more complex, working memory management becomes critical — you can’t fit an entire enterprise knowledge base into a single context window, so agents need strategies for deciding what’s most relevant to pull in.
Shared memory is information that multiple agents in the system can access — a shared workspace where one agent can write results that another agent reads. Think of this as a whiteboard that the whole team can see. In practice, shared memory is implemented as a database, a vector store, or a structured file that agents read from and write to as the workflow progresses.
Long-term memory is what the system retains across multiple tasks — patterns it has learned, preferences it has observed, historical context that’s relevant to recurring workflows. This is the most complex memory layer to implement and is often deferred to a later stage of deployment.
Component 4 — The Tool Layer: How Agents Interact With the Real World
Agents become useful when they can take actions — querying databases, calling APIs, reading documents, sending messages, updating records. The tool layer defines what each agent can do and what systems it can touch.
Designing the tool layer requires the same discipline as any other security-sensitive system access decision: every agent should have access only to the tools it needs for its specific role. An agent that summarises documents should not have write access to your CRM. An agent that drafts customer emails should not have access to your financial data.
This isn’t just good security practice — it’s also good architecture. Agents with tightly scoped tool access are more predictable and easier to debug when something goes wrong. Agents with broad tool access produce broader failure modes.
Practically, the tool layer is built using function-calling capabilities in modern LLMs — where the model can call a defined set of functions (search the web, query a database, send an HTTP request) and receive the results back as part of its context. Frameworks like LangChain, LlamaIndex, and Microsoft AutoGen provide structured ways to define and manage these tool sets.
Component 5 — The Communication Protocol: How Agents Talk to Each Other
Agents in a multi-agent system pass information to each other — the output of one agent becomes an input for another. How that handoff is structured determines whether the system behaves predictably or devolves into garbage-in, garbage-out chains.
The two main communication patterns are:
Sequential (pipeline): Agent A completes its task and passes the output to Agent B, who passes to Agent C, and so on. Simple to reason about and debug. Limited because Agent C can’t ask Agent A a follow-up question if something is unclear.
Hierarchical (manager-worker): The orchestrator assigns tasks, agents report back, the orchestrator can reassign or ask for revisions before moving to the next step. More flexible and produces better outputs for complex tasks. Harder to build and more expensive to run because the orchestrator model handles more interactions.
For most enterprise use cases that involve multiple rounds of information gathering and synthesis, the hierarchical pattern produces significantly better results — at the cost of more LLM API calls and therefore higher operational cost.
🔑 KEY TAKEAWAYS — The Architecture
- Multi-agent systems assign specialised work to specialist agents coordinated by an orchestrator
- The orchestrator’s task decomposition logic is the most critical design decision in the system
- Memory has three layers: working (in-context), shared (cross-agent whiteboard), and long-term (cross-task)
- Tool access should be tightly scoped per agent — don’t give agents permissions beyond their specific role
- Sequential pipelines are simpler; hierarchical orchestration produces better results for complex tasks
The Decision Matrix: What to Build, Buy, or Use From an Open-Source Framework
Most enterprise teams building multi-agent systems for the first time don’t need to build every component from scratch. Here’s how to think about the build/buy/framework decision for each component:
| Component | Build From Scratch | Use a Framework | Buy a Platform |
| Orchestration logic | Full control, high cost | LangChain, AutoGen, CrewAI — best default | Emerging SaaS options — limited customisation |
| Specialist agents | Best for proprietary models or fine-tuned use cases | Mix of foundation models via API — most practical | Vendor-specific agents — limited to vendor’s tool set |
| Memory management | Needed for custom long-term memory | LlamaIndex for RAG-based memory; vector DBs (Pinecone, Weaviate) | Database platforms — Postgres, MongoDB for structured memory |
| Tool integrations | Required for proprietary internal systems | Pre-built connectors in LangChain / AutoGen cover most standard APIs | iPaaS tools (Zapier, Make) for non-technical teams |
| Observability | Complex to build well | LangSmith, Arize AI — purpose-built, use these | Included in some enterprise AI platforms |
The practical recommendation for most enterprises:
- Use an orchestration framework (LangChain or AutoGen are the most mature) rather than building orchestration from scratch
- Build specialist agents using foundation model APIs (OpenAI, Anthropic, Google) rather than maintaining your own model infrastructure
- Build custom tool integrations for proprietary internal systems — this is where proprietary value lives
- Implement purpose-built observability from day one — LangSmith for LangChain-based systems, Arize AI for broader deployments
Common Architecture Mistakes- and How to Avoid Them
Mistake 1: Making the Orchestrator Do Too Much
A common pattern in early multi-agent designs is an orchestrator that handles not just coordination but also complex reasoning, data retrieval, and output synthesis — essentially doing the work of the specialist agents itself. This defeats the purpose of the architecture and creates a single point of failure.
The fix: define the orchestrator’s role precisely — coordination and task assignment only. Any task that requires substantive work should be delegated to a specialist agent, even if the orchestrator could technically do it.
Mistake 2: No Error Handling Between Agents
In a single-agent system, when the agent fails, it fails visibly — you get an error or a blank response. In a multi-agent system, when one agent fails or produces poor output, the next agent in the chain receives that poor output and tries to work with it. By the time the failure reaches the end of the pipeline, the original error is buried under layers of downstream processing.
Every agent-to-agent handoff needs an explicit validation step: does the output from Agent A meet the quality threshold required for Agent B to do useful work? If not, the system should either retry, escalate to a human, or fail gracefully with a clear error — not continue silently with bad data.
Mistake 3: Skipping Observability Until Something Goes Wrong
Multi-agent systems are significantly harder to debug than single-agent systems. When an output is wrong, was it the orchestrator’s task decomposition? Agent B’s reasoning? A tool call that returned unexpected data? Without logs of every agent interaction, every tool call result, and every inter-agent message, diagnosing production failures is essentially guesswork.
Implement logging and tracing before your first production deployment — not after your first production failure.
Mistake 4: Designing for the Happy Path
Demo environments show what happens when everything works. Production environments are where you discover what happens when Agent B times out, when a tool returns an empty result, when the orchestrator receives contradictory outputs from two agents, when a context window fills up mid-task.
Design your failure modes explicitly before you go live: what should happen in each of these scenarios? Most production multi-agent failures are not catastrophic model errors — they are edge cases that nobody designed for.
KEY TAKEAWAYS Common Mistakes
- Orchestrators that do too much become single points of failure — keep them in a coordination role only
- Agent-to-agent handoffs need validation steps — silent propagation of bad outputs is the most common failure mode
- Observability is not optional — you cannot debug a multi-agent system you can’t see inside
- Design for failure modes explicitly — what the system does when something goes wrong is as important as what it does when everything works
A Reference Architecture: Multi-Agent Claims Processing for Financial Services
Here is how the five components come together in a realistic enterprise deployment, a multi-agent system for insurance claims processing.
The workflow: A customer submits an insurance claim. The system needs to verify coverage, assess the claim against policy terms, flag potential fraud indicators, calculate the settlement amount, and draft the response to the customer.
The architecture:
| Agent | Role | Tools Available | Model Choice |
| Orchestrator | Receives claim, assigns tasks, assembles final output | None (coordination only) | GPT-4o |
| Coverage Verification Agent | Checks policy database for coverage applicability | Policy database query | GPT-4o Mini |
| Claims Assessment Agent | Compares claim details against policy terms | Document reader, policy terms DB | Claude 3.5 Sonnet |
| Fraud Detection Agent | Scores claim against fraud indicators | Fraud signals database, claims history | Fine-tuned classifier |
| Settlement Calculation Agent | Computes settlement based on coverage and assessment | Financial calculation tools | GPT-4o Mini |
| Communication Agent | Drafts customer response in approved tone | None (generation only) | Claude 3.5 Sonnet |
Memory design:
- Working memory: each agent receives only the information needed for its specific task
- Shared memory: a structured claims record that each agent reads from and writes its outputs to
- Long-term memory: fraud patterns and claims history from previous cases
Communication pattern: Hierarchical the orchestrator collects each agent’s output, validates quality, and coordinates the next step rather than running a fixed pipeline.
Estimated outcome: A workflow that previously required 3–4 human reviewers and 2–3 days to complete can be processed in under 10 minutes with human review reserved for flagged edge cases only.
What’s Coming Next: The Next 18 Months in Multi-Agent Systems
Two developments are worth building your architectural decisions around right now.
Standardised agent communication protocols are emerging.
One of the current friction points in multi-agent systems is that agents built on different frameworks — a LangChain orchestrator talking to an AutoGen specialist agent — don’t have a common language. Anthropic’s Model Context Protocol (MCP) and OpenAI’s emerging agent communication standards are beginning to address this. Architectures built with interoperability in mind today will require less rework as these standards mature.
Multi-agent systems are becoming more self-correcting.
Current architectures require explicit error-handling logic to be built in by developers. The next generation of orchestration frameworks is incorporating native self-correction — agents that can identify when their output doesn’t meet quality criteria and automatically revise before passing to the next step. This will significantly reduce the engineering effort required for robust production deployments.
Conclusion
Multi-agent systems are not science fiction and they are not just for technology companies. They are a practical architectural pattern that is already running in production in financial services, healthcare, logistics, and SaaS — handling workflows that single-agent systems simply cannot do reliably.
The organisations that will lead with this capability in two years are the ones that understand the architecture now: what the five components are, how they interact, where the failure modes live, and what to build versus buy.
The blueprint is here. The frameworks exist. The foundation models are capable enough. What separates the organisations that successfully deploy multi-agent systems from those that build expensive demos is the same thing that separates any successful enterprise technology deployment: rigorous architecture, honest failure mode design, and observability from day one.
Frequently Asked Questions
A multi-agent AI system is a design where multiple AI agents work together on a task — each one specialising in a specific type of work, coordinated by an orchestrator that manages the overall workflow. Think of it as an AI team rather than a single AI employee. Each specialist agent does one thing well — researching, writing, checking, calculating — and the orchestrator coordinates their work and assembles the final output. Multi-agent systems are used when a task is too complex or multi-dimensional for a single AI agent to handle reliably.
A single AI agent handles a complete task from start to finish on its own — one model, one context, one sequential workflow. A multi-agent system distributes the work across multiple specialised agents that each handle one component of a larger task. Single agents are simpler and cheaper to build and run. Multi-agent systems produce significantly better results for complex, multi-step workflows — at the cost of more architectural complexity and higher operational cost. The right choice depends on whether your use case genuinely requires multiple types of expertise or can be handled reliably by one well-prompted agent.
The most widely used frameworks for enterprise multi-agent systems are LangChain (the most mature, with extensive tool integrations and community support), Microsoft AutoGen (purpose-built for multi-agent coordination with strong support for hierarchical agent patterns), and CrewAI (more opinionated about agent roles and collaboration patterns, good for teams new to multi-agent design). For observability, LangSmith integrates natively with LangChain; Arize AI and Weights & Biases work across frameworks. Most production enterprise deployments use one of these frameworks rather than building orchestration logic from scratch.
The four most common production failures are: (1) error propagation — bad output from one agent silently corrupts the inputs for subsequent agents; (2) context window overflow — agents receive more information than they can process effectively, producing degraded outputs; (3) orchestrator overload — the orchestrator is asked to do substantive reasoning work in addition to coordination, becoming a performance bottleneck; and (4) unhandled edge cases — the system was designed for the expected workflow but has no defined behaviour when something unexpected happens. All four are preventable with explicit design decisions before deployment.
Cost depends primarily on: the number of agents, the complexity of tasks they handle, the foundation models used, and the volume of tasks processed. A rough benchmark: a moderately complex multi-agent workflow using GPT-4o for the orchestrator and GPT-4o Mini for specialist agents might cost $0.05–$0.50 per workflow completion, depending on task complexity. High-volume deployments benefit significantly from using cheaper models for simpler agents and reserving expensive models for complex reasoning tasks. Observability tooling adds a modest additional cost. Most organisations find that even at $0.50 per completion, multi-agent automation of complex workflows is dramatically cheaper than the human equivalent.
Yes, but with important design considerations. Regulated industries need audit trails for AI decisions — the logging and observability layer in a multi-agent system actually makes it more auditable than human workflows in many cases, because every step is logged. The key requirements for regulated deployments are: human review for high-stakes decisions (the system proposes, a human approves), complete audit trails of every agent action and output, clear accountability mapping (which team owns the system, who reviews flagged outputs), and alignment with relevant frameworks (NIST AI RMF, SR 11-7 for financial services, HIPAA for healthcare). The financial services claims processing example in this article is a real deployment pattern being used in production at several insurers.
NIST’s AI Risk Management Framework (AI RMF), published in 2023, provides guidance for managing risks associated with AI systems across four functions: Govern, Map, Measure, and Manage. It applies to multi-agent systems as it does to any enterprise AI deployment. For multi-agent systems specifically, the most relevant NIST guidance covers transparency and explainability of AI decisions (the logging and observability layer), human oversight requirements (approval gates for high-stakes actions), and accountability structures (who owns and is responsible for the system’s outputs). The AI RMF is voluntary in the US but is increasingly referenced in enterprise procurement requirements and is likely to inform future regulatory requirements.